找到
531
篇与
潼语
相关的结果
- 第 105 页
-
 去除首页前台登录按钮 前言 本教程主要目的是去除主页的登录按钮,去除首页前台登录按钮,登陆后,显示登录状态,不登录即消失。 教程 找到头部文件header.php一般的路径地址是:usr/themes/Joe/public/header.php 注释第 217 行到 218 行的 html 代码 即包含登录注册的 <?php else : ?> 代码 <?php else : ?> <div class="item"> <svg class="icon" viewBox="0 0 1024 1024" xmlns="http://www.w3.org/2000/svg" width="15" height="15"> <path d="M710.698 299a213.572 213.572 0 1 0-213.572 213.954A213.572 213.572 0 0 0 710.698 299zm85.429 0a299.382 299.382 0 1 1-299-299 299 299 0 0 1 299 299z" /> <path d="M114.223 1024a46.91 46.91 0 0 1-46.91-46.91 465.281 465.281 0 0 1 468.332-460.704 475.197 475.197 0 0 1 228.827 58.35 46.91 46.91 0 1 1-45.384 82.378 381.378 381.378 0 0 0-183.443-46.909 371.08 371.08 0 0 0-374.131 366.886A47.29 47.29 0 0 1 114.223 1024zM944.483 755.129a38.138 38.138 0 0 0-58.733 0l-146.449 152.55-92.675-91.53a38.138 38.138 0 0 0-58.732 0 43.858 43.858 0 0 0 0 61.402l117.083 122.422a14.492 14.492 0 0 0 8.39 4.577c4.196 0 4.196 4.195 8.39 4.195h32.037c4.195 0 4.195-4.195 8.39-4.195s4.195-4.577 8.39-4.577L946.39 816.15a48.054 48.054 0 0 0-1.906-61.02z" /> <path d="M763.328 776.104L730.53 744.45a79.708 79.708 0 0 0 32.798 31.654" /> </svg> <a href="<?= joe\user_url('login'); ?>" rel="noopener noreferrer nofollow">登录</a> <?php if ($this->options->allowRegister) : ?> <span class="split">/</span> <a href="<?= joe\user_url('register'); ?>" rel="noopener noreferrer nofollow">注册</a> <?php endif; ?> </div> <?php endif; ?>总结 教程到此结束
去除首页前台登录按钮 前言 本教程主要目的是去除主页的登录按钮,去除首页前台登录按钮,登陆后,显示登录状态,不登录即消失。 教程 找到头部文件header.php一般的路径地址是:usr/themes/Joe/public/header.php 注释第 217 行到 218 行的 html 代码 即包含登录注册的 <?php else : ?> 代码 <?php else : ?> <div class="item"> <svg class="icon" viewBox="0 0 1024 1024" xmlns="http://www.w3.org/2000/svg" width="15" height="15"> <path d="M710.698 299a213.572 213.572 0 1 0-213.572 213.954A213.572 213.572 0 0 0 710.698 299zm85.429 0a299.382 299.382 0 1 1-299-299 299 299 0 0 1 299 299z" /> <path d="M114.223 1024a46.91 46.91 0 0 1-46.91-46.91 465.281 465.281 0 0 1 468.332-460.704 475.197 475.197 0 0 1 228.827 58.35 46.91 46.91 0 1 1-45.384 82.378 381.378 381.378 0 0 0-183.443-46.909 371.08 371.08 0 0 0-374.131 366.886A47.29 47.29 0 0 1 114.223 1024zM944.483 755.129a38.138 38.138 0 0 0-58.733 0l-146.449 152.55-92.675-91.53a38.138 38.138 0 0 0-58.732 0 43.858 43.858 0 0 0 0 61.402l117.083 122.422a14.492 14.492 0 0 0 8.39 4.577c4.196 0 4.196 4.195 8.39 4.195h32.037c4.195 0 4.195-4.195 8.39-4.195s4.195-4.577 8.39-4.577L946.39 816.15a48.054 48.054 0 0 0-1.906-61.02z" /> <path d="M763.328 776.104L730.53 744.45a79.708 79.708 0 0 0 32.798 31.654" /> </svg> <a href="<?= joe\user_url('login'); ?>" rel="noopener noreferrer nofollow">登录</a> <?php if ($this->options->allowRegister) : ?> <span class="split">/</span> <a href="<?= joe\user_url('register'); ?>" rel="noopener noreferrer nofollow">注册</a> <?php endif; ?> </div> <?php endif; ?>总结 教程到此结束
-
8月21日全服更新维护公告 8月21日全服更新维护公告 更新图片 各位庄园的亲们,早上好! 今天是8月21日。上午,全服计划按双子、狮子座服务器的顺序进行本周的更新维护。时间预计为上午9点00分~13点(如在预计时间内无法完成相应内容,服务器开启时间将顺延)请各位玩家相互转告并提前下线,感谢大家的理解与配合。 以下为本次更新内容预告: 1、“心语心愿”下架:游玩潜水艇、沙滩游泳池、海景度假酒店,普通和精华套装。 2、本周更新后—9月1日23:59,贸易中心上线第42期“心语旧品回收活动”。活动结束后积分不保留,活动每天将对积分数据进行检查,发现有刷积分等BUG现象,兑换物品全部删除,账户封停。 PS:为维护游戏环境,保护玩家利益,请不要线下、淘宝等方式大量购买游戏物品。此类物品无法保证来源正常,非法物品一经查出,将进行删除、封号等相应处理。 《浪漫庄园》运营团队 2024.8.21
-
浪漫庄园公告自动发布 前言 当前脚本使用的开发语言是Python,功能是通过脚本的运行获取浪漫庄园每次游戏更新后的更新内容,并且通过钉钉api将内容实时发送到钉钉群内。 教程 第一步 在代码开头将编码设置为“gbk” # -*- coding: gbk -*-设置这一步是防止后续出现乱码的问题 第二步 需要添加相关的扩展 from sqlite3 import Timestamp import requests import chardet from bs4 import BeautifulSoup from datetime import datetime import mysql.connector import re其中需要安装的有:requests、bs4、mysql 第三步 数据库配置 # MySQL数据库配置 db_config = { 'user': 'user', //数据库用户名 'password': 'password', //数据库密码 'host': 'ip', //数据库IP地址 'database': 'database', //数据库名 'raise_on_warnings': True # 要保存的表名 table_name = 'huancun' //将“huancun”换成自己数据库中定义的表名 } 第四步 获取网页中需要的内容 def format_current_date(): # 获取当前日期 now = datetime.now() # 提取年份的后两位 year_last_two = str(now.year)[-2:] # 提取月份和日期的两位数字 month_two = str(now.month).zfill(2) # zfill确保总是两位数字 day_two = str(now.day).zfill(2) # 同上 # 组合成字符串并加上01 formatted_date = year_last_two + month_two + day_two + '01' return formatted_date def get_webpage_text_content(url_template): try: # 假设URL模板是 http://rc.leeuu.com/data/news/{date}.htm formatted_date = format_current_date() url = url_template.format(date=formatted_date) #url = url_template.format(date='24062601') response = requests.get(url) # 尝试检测编码(如果响应内容不是UTF-8) raw_data = response.content if not response.encoding.lower() == 'utf-8': result = chardet.detect(raw_data) encoding = result['encoding'] content = raw_data.decode(encoding, errors='ignore') # 使用检测到的编码解码 else: content = response.text # 如果已经是UTF-8,则直接使用text # 确保请求成功 if response.status_code == 200: # 使用BeautifulSoup解析HTML soup = BeautifulSoup(content, 'html.parser') # 提取所有文本内容(包括段落、标题等) text_content1 = soup.get_text(strip=True, separator='\n') # strip=True 去除多余空白,separator='\n' 以换行符分隔文本块 text_content = re.sub(r'(搜索.*\n复制.*)', '', text_content1, flags=re.DOTALL | re.MULTILINE) return text_content else: return f"Failed to retrieve the webpage. Status code: {response.status_code}" #报告网页错误 except requests.RequestException as e: return f"Oops: Something Error {e}" except UnicodeDecodeError as e: return f"Error decoding the webpage: {e}" 第五步 # 发送钉钉文本消息的函数 def send_dingtalk_text_message(content, webhook_url): headers = { 'Content-Type': 'application/json', 'Charset': 'UTF-8', } message = { "msgtype": "text", "text": { "content": content } } try: response = requests.post(webhook_url, json=message, headers=headers) response.raise_for_status() # 如果请求失败,抛出HTTPError异常 print("DingTalk text message sent successfully.") except requests.RequestException as e: print(f"Error sending DingTalk text message: {e}") #send_dingtalk_text_message("今日暂无更新", DINGTALK_WEBHOOK_URL) # 钉钉Webhook的URL DINGTALK_WEBHOOK_URL = 'https://oapi.dingtalk.com/robot/send?access_token=XXXX' //将XXXX替换为自己钉钉群内自定义机器人中的数据 # 使用URL模板 url_template = "http://rc.leeuu.com/data/news/{date}.htm" content = get_webpage_text_content(url_template)第六步 连接数据库并且添加获取到的内容进数据库,同时向钉钉群内发送消息 # 假设这是你从某个数据源获取的新内容及其相关信息 if "404" in content: new_content = "今日无更新内容。" else: new_content = content new_key_value = format_current_date() timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间戳 # 连接到MySQL数据库 cnx = mysql.connector.connect(**db_config) cursor = cnx.cursor() # 定义表名和字段 table_name = "huancun" key_field = 'key' # 替换为你的唯一键字段名 content_field = 'content' # 内容字段名 timestamp_field = 'timestamp' # 时间戳字段名 # 执行查询 query = f"SELECT {content_field} FROM {table_name} WHERE `{key_field}` = %s" cursor.execute(query, (new_key_value,)) # 使用参数化查询来防止SQL注入 # 获取查询结果 result = cursor.fetchone() # 因为是根据主键查询,所以预期只返回一个结果 # 检查 result 是否存在 if result: content1 = result[0] if content1 == new_content: print("当前数据未更新!") else: # 使用 f-string 构建 SQL 查询 insert_query = f""" INSERT INTO `{table_name}` (`{key_field}`, `{content_field}`, `{timestamp_field}`) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE `{content_field}` = VALUES({content_field}), `{timestamp_field}` = VALUES({timestamp_field}) """ try: cursor.execute(insert_query, (new_key_value, new_content, timestamp)) cnx.commit() print("新内容已保存到数据库,或已存在的记录已更新。") if "404" not in new_content: send_dingtalk_text_message(new_content, DINGTALK_WEBHOOK_URL) except Exception as e: print(f"发生错误:{e}") else: # 如果没有找到记录,直接插入新数据 insert_query = f""" INSERT INTO `{table_name}` (`{key_field}`, `{content_field}`, `{timestamp_field}`) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE `{content_field}` = VALUES({content_field}), `{timestamp_field}` = VALUES({timestamp_field}) """ try: cursor.execute(insert_query, (new_key_value, new_content, timestamp)) cnx.commit() print("新内容已保存到数据库,或已存在的记录已更新。") if "404" not in new_content: send_dingtalk_text_message(new_content, DINGTALK_WEBHOOK_URL) except Exception as e: print(f"发生错误:{e}") # 关闭游标和连接 cursor.close() cnx.close()代码到此完毕,后续根据实际情况会进行优化删减,使代码运行更加方便 第七步 最后一步将文件上传到服务器上,添加定时任务中的shell脚本填写以下代码: sudo -u root bash -c '#!/bin/bash . /etc/profile . ~/.bash_profile /usr/bin/XX /XXX/XXX/浪漫庄园公告.py'
-
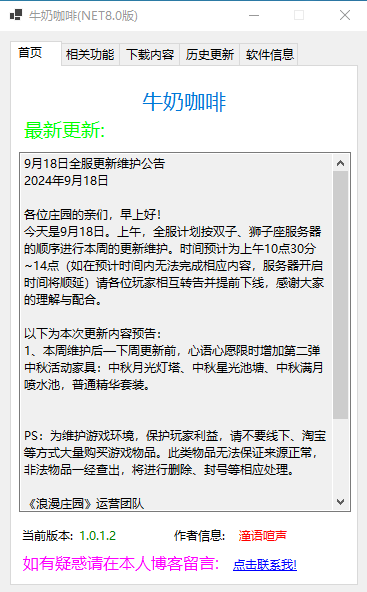
牛奶咖啡更新日志 前言 本工具使用C#搭载NET Croe 8.0框架编译而成,软件功能单一更多功能慢慢开发中,仅供自己娱乐使用版本说明 从1.43.3.1版本开始将不按照顺序填写版本号,以此版本为例:1表示大版本号;43表示今年的第几周;3表示当周的第几天更新的;最后的1表示小版本号效果图 效果图图片 更新历程 {collapse-item label="详细更新说明" close} 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b ed4014 {/collapse-item} 下载地址 目前仅供个人使用,暂未开发开放版本!!!
-
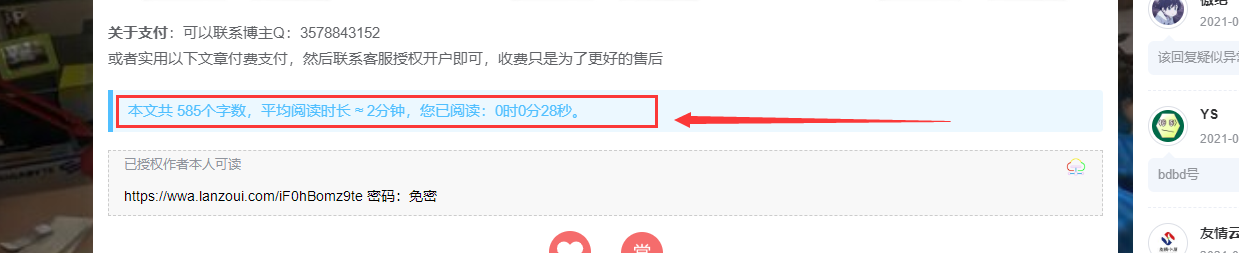
【Typecho】的Joe主题新增文章阅读时长统计 成品演示 效果图图片 教程开始 第一步 修改 functions.php 文件,底部增加,文件路径: /usr/themes/Joe 注意:代码一定要在</>之间,否则会报错 // 文章阅读时长设置 $onlineTime = new Typecho_Widget_Helper_Form_Element_Select( 'onlineTime', array( 'off' => '关闭(默认)', 'on' => '开启', ), 'on', '是否启用文章阅读时长统计', '介绍:开启后,文章底部展示文章字数,预计阅读时长和已阅读时长' ); $onlineTime->setAttribute('class', 'joe_content joe_post'); //如果设置无法展示,请将joe_custom替换为joe_other $form->addInput($onlineTime->multiMode());截图说明:图片 第二步 2.修改 article.php 文件,文件路径: usr/themes/Joe/module/single <div class="contain" style="margin-bottom: 10px; <?php if(Helper::options()->onlineTime !== 'on') echo 'display:none;' ?>"> <blockquote id="onlineTime">本文共 <?php art_count($this->cid); ?> 个字数,平均阅读时长 ≈ <?php echo art_time($this->cid); ?>分钟</blockquote> </div>截图说明:图片 第三步 3.修改 article.php 文件,文件路径: usr/themes/Joe/module/single 在最底部添加以下代码: <?php //文章阅读时间统计 function art_time ($cid){ $db=Typecho_Db::get (); $rs=$db->fetchRow ($db->select ('table.contents.text')->from ('table.contents')->where ('table.contents.cid=?',$cid)->order ('table.contents.cid',Typecho_Db::SORT_ASC)->limit (1)); $text = preg_replace("/[^\x{4e00}-\x{9fa5}]/u", "", $rs['text']); $text_word = mb_strlen($text,'utf-8'); echo ceil($text_word / 400); } //文章字数统计 function art_count ($cid){ $db=Typecho_Db::get (); $rs=$db->fetchRow ($db->select ('table.contents.text')->from ('table.contents')->where ('table.contents.cid=?',$cid)->order ('table.contents.cid',Typecho_Db::SORT_ASC)->limit (1)); $text = preg_replace("/[^\x{4e00}-\x{9fa5}]/u", "", $rs['text']); echo mb_strlen($text,'UTF-8'); } ?> <script language="javascript"> var second=0; var minute=0; var hour=0; window.setTimeout("interval();",1000); function interval() { second++; if(second==60) { second=0;minute+=1; } if(minute==60) { minute=0;hour+=1; } var onlineTime = "您已阅读:" + hour + "时" + minute + "分" + second + "秒。"; var joe_message_content = "本文共 " + <?php art_count($this->cid); ?> + "个字数,平均阅读时长 ≈ " + <?php echo art_time($this->cid); ?> + "分钟,"; $('#onlineTime').text(joe_message_content + onlineTime); window.setTimeout("interval();", 1000); } </script>截图说明:图片